Full Crete Demo - 05.09.2024
This demo page is a guideline for the 05.09.2024 demo of the dAIEdge-VLab.
Usefull Links
Access the dAIEdge-VLab.
Models
Download here all the models used in the demo.
Introduction
Estimated time : 30 seconds
Presenters :
- Huguenin-Vuillemin Maïck
- Baptiste Dupertuis
- Pazos Escudero Nuria
Key talking points :
- dAIEdge-VLab : The dAIEdge-VLab is a platform that allows to benchmark models on different devices.
- Benchmark : The benchmark is a way to measure the performance of a model on a device.
- Target : The target is the device on which the benchmark will be run.
Demo 1 - User Case
Estimated time : 3 minutes
Open Navigator
Open the navigator in prive browsing and go to http://157.26.64.222/benchmark.
Key talking points :
- First Page : The first page is the dAIEdge-VLab’s home page. Explains what we are about to do.
- prive browsing is important to avoid any cache issue.
- http : The dAIEdge-VLab doesn’t use yet https. It will come soon.
Fill the form
Fil the form with the following information :
- Target :
Raspberry Pi 5 - Runtime :
ONNX Runtime - Model :
small_model.onnx
Click on the Launch the benchmark button.
Key talking points :
- Target : The target is the device on which the benchmark will be run.
- Runtime : The runtime is the framework used to run the benchmark. Here ONNX Runtime is used, but other runtimes are available.
- Model : The model is the file that contains the model to be benchmarked. There a small model is used to get a quick result.
Wait for the results
The result should be available in about 20 seconds.
Key talking points :
- Events :
- Start : The dAIEdge-VLab looks for an available runner that has the Target attached to. It then sends the model to the runner with other parameters.
- Benchmark : The runner runs all the scripts and perform the benchmark.
- End : The results are sent back to the dAIEdge-VLab and displayed to the user.
Analyse the results
Key talking points :
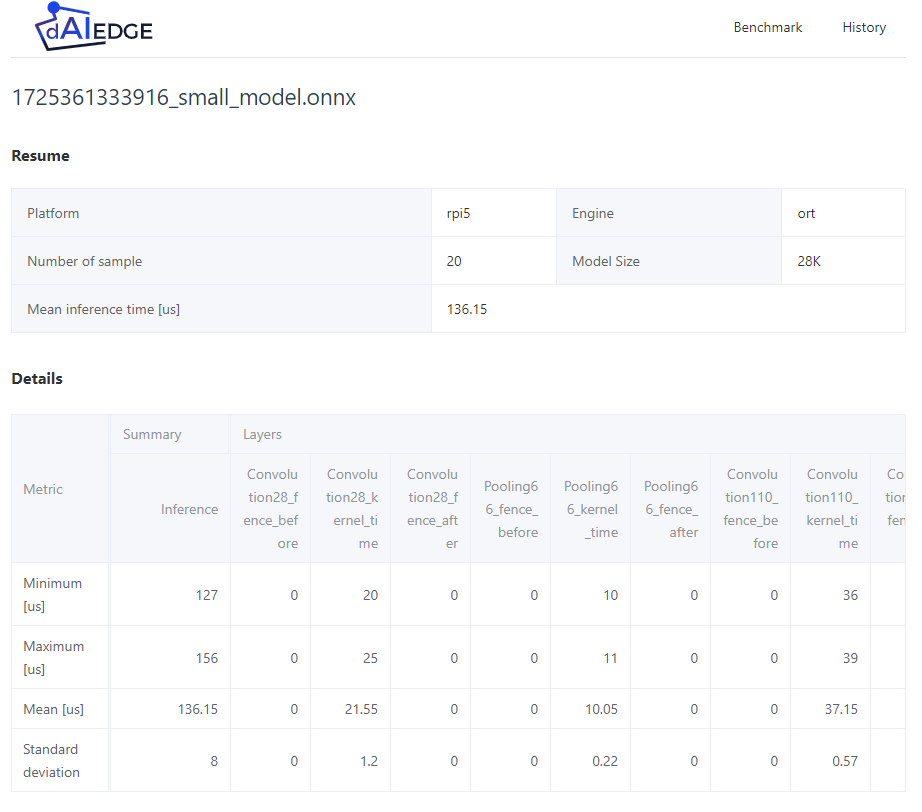
- General result : Disply the general result of the benchmark.
- Layer by layer result : Display the latency result of each layer of the model.
- Viszaulisation : The result can be visualized in different graphs.
- Imporvement : The dAIEdge-VLab is still in development, the result page is planded to be greatly improved.
 In case of problems :
In case of problems :
- Here is the resulting JSON.
- Here is the pipeline of the same benchmark.
History
Go to the history page and show the previous results and the possibility to download them.
Key talking points :
- History : The history page contains all the previous results of the user.
- Download : The user can download the result in JSON format.
- Delete : The user can delete the result from the history.
- Re-upload : The user can re-upload the result to see it again.
- Compare : The user can compare the result with other results. We will see that in the next demo.
Demo 2 - MCU Target and pipelines
Estimated time : 5 minutes
Fill the form
Go to http://157.26.64.222/benchmark.
Fil the form with the following information :
- Target :
NXP Cup board, MCU LPC55S69JBD100 - Runtime :
TensorFlow Lite - Model :
small_model.tflite
Click on the Launch the benchmark button.
Key talking points :
- Target : The target this time is an MCU based on a Cortex M33.
- Runtime : The runtime is ThensoFlow Lite for microcontrollers. This benchmark will take more time than the previous one.
- Model : The selected model is very small, this target has very limited memory resources.
Wait for the results & show the pipeline
The result should be available in about 3 minutes.
Got to the pipeline page and show the different steps of the benchmark. Key talking points :
- Pipeline : The pipeline is the set of steps that are executed to run the benchmark.
- Runner : The runner is selected by the VirtualLab based on the Runner tags.
- Steps :
- Prepare : The VirtualLav prepares the environment. It downloads the model and the target sources to the runner.
- Run : The VirtualLab runs the different scripts to perform the benchmark.
- Upload : The runner uploads the result to the VirtualLab.
- End : The VirtualLab displays the result to the user.
Analyse the results
Key talking points :
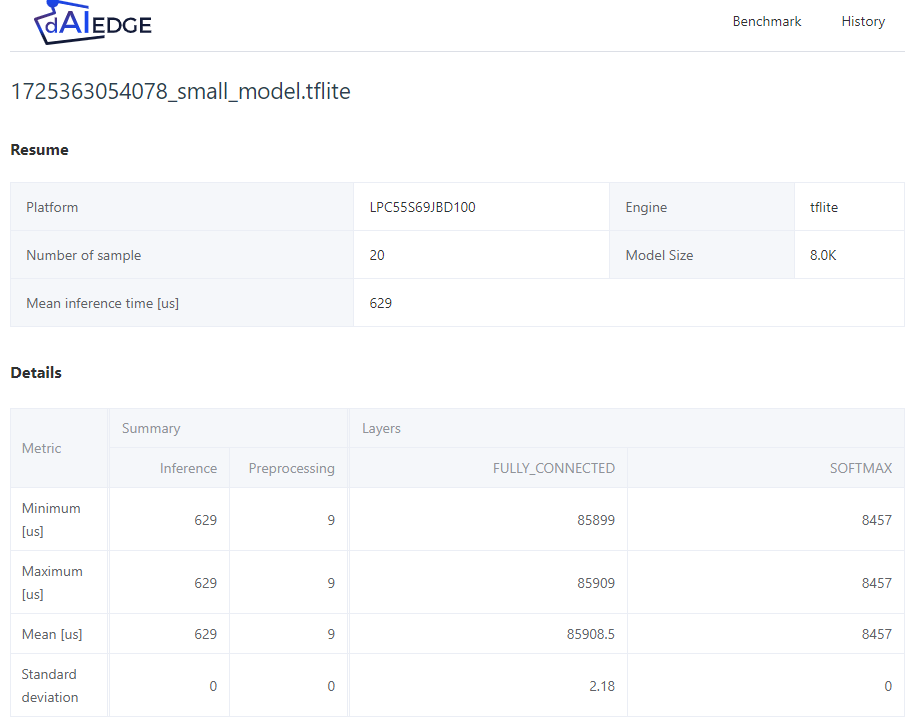
- Small Model : The model is very small, the inference time is low.
In case of problems :
- Here is the resulting JSON.
- Here is the pipeline of the same benchmark.
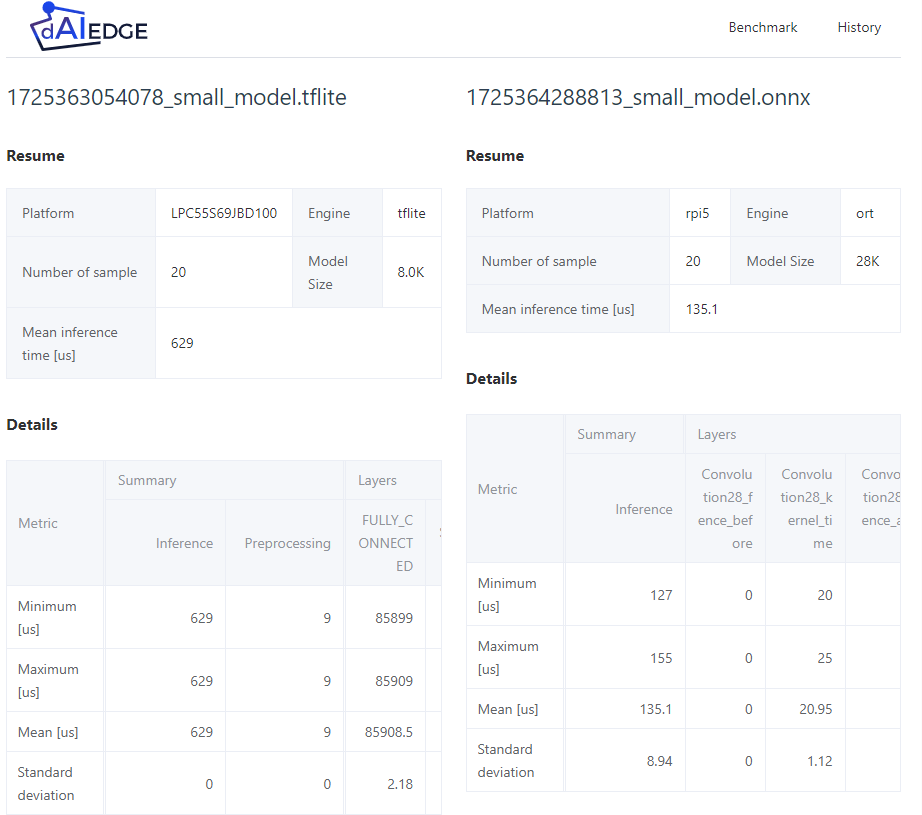
Compare the results
Go to the history page and compare the two results.
Key talking points :
- Models : The models used and the targets are different. Thus comparing the results is not relevant. But here is just to illustrate the feature.
Demo 3 - MPU Target and Target structure
Estimated time : 4 minutes
Fill the form
Go to http://157.26.64.222/benchmark.
Fil the form with the following information :
- Target :
Jetson Orin Nano - Runtime :
TensorRT - Model :
big_model.onnx
Click on the Launch the benchmark button.
Key talking points :
- Target : The target is a Jetson Orin Nano, a powerful device with a GPU.
- Runtime : The runtime is TensorRT, a runtime optimized for NVIDIA GPUs.
- Model : The model is a big model, for embedded standards. It will take more time to run.
Wait for the results & show the pipeline
The result should be available in about 3 minutes.
Go to the targets repository page and show the different repository. Select and show the JetsonOrinNano_TRT.
Here is an MCU repository for the LPC55S69_TFLite.
Key talking points :
- Structure : The structure of the target repository is important. It contains all the scripts and files needed to run the benchmark.
- AI_Support : Prepare the environment and generate the appropriate code for the target if needed.
- AI_Build : Build the target code.
- AI_Deploy : Deploy the model and the target code to the target.
- AI_Manager : Run the benchmark and measure the performance.
- AI_Project : Contains the target project and code base.
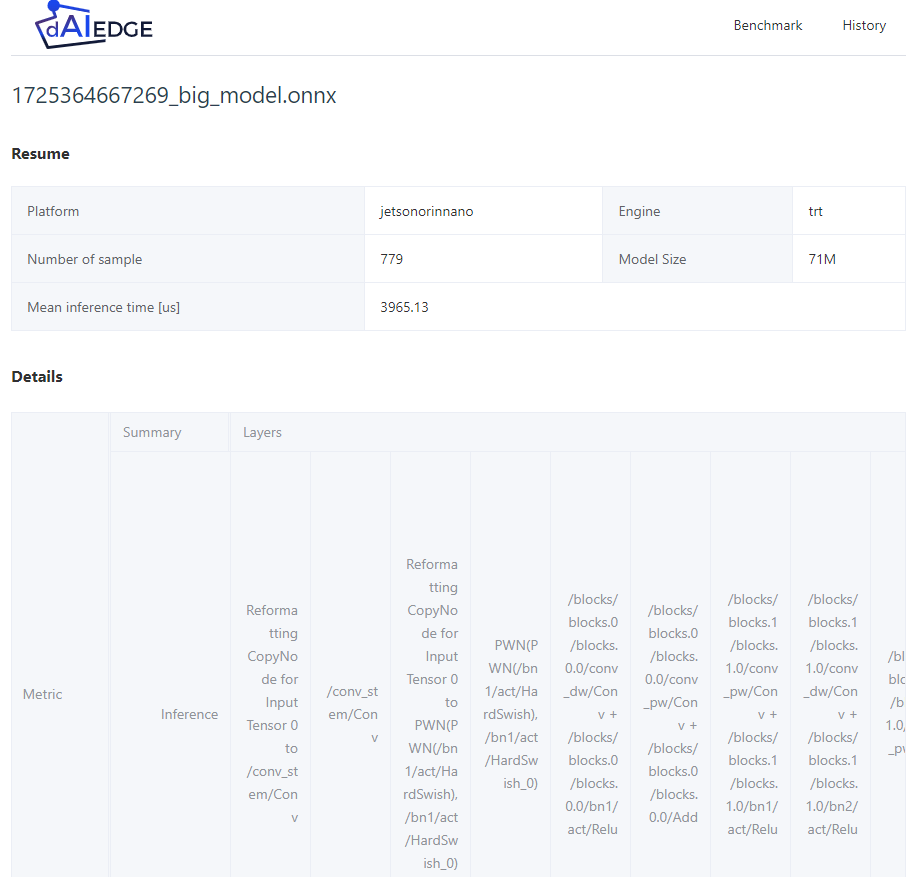
Analyse the results
Key talking points :
- Model : Big model, the result visualization is more complex and will be improved in the future.
In case of problems :
- Here is the resulting JSON.
- Here is the pipeline of the same benchmark.
Demo 4 - Error handling
Estimated time : 3 minutes
Fill the form
Go to http://157.26.64.222/benchmark.
Fil the form with the following information :
- Target :
IOT board, MCU STM32L4R9 - Runtime :
X-Cube-AI - Model :
big_model.onnx
Click on the Launch the benchmark button.
Key talking points :
- Target : The target is a Cortex M4 from ST.
- Runtime : The runtime is X-Cube-AI, a runtime optimized for STM32.
- Model : The model is a big model and the target doesn’t have enough memory. This will generate an error.
Wait for the results
The result should be available in about 1 minutes.
Analyze the results
Key talking points :
- Error : The error is displayed to the user. All the pipeline result is shown to the user. This will change in the future, the error will be more explicit and focused on the error.
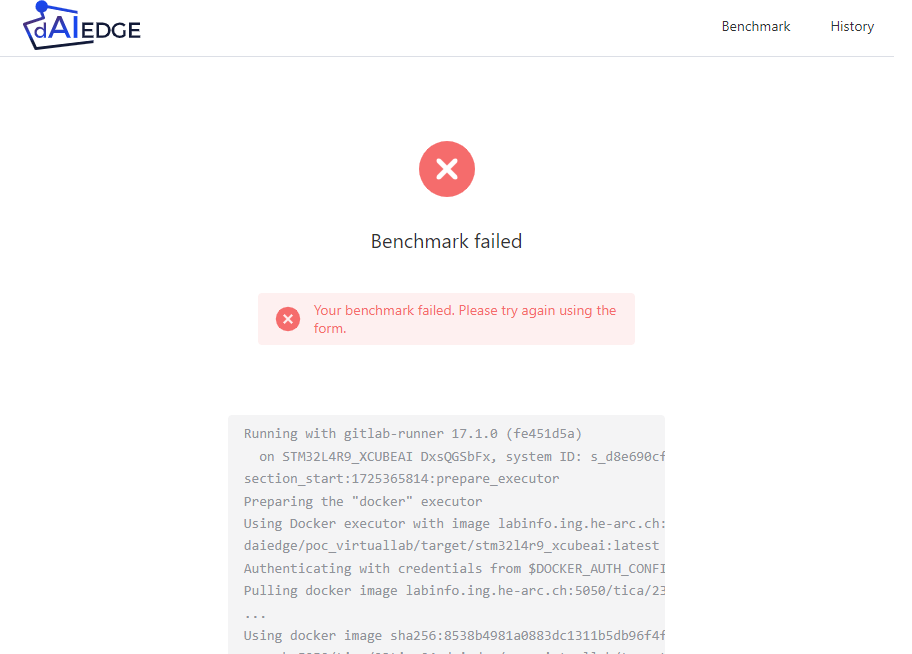 Here is the pipeline of the same benchmark.
Here is the pipeline of the same benchmark.
Conclusion
Documentation is available for user and developers. The documentation is available here.